╔╠śI(y©©)ųŪ─▄į┌CRMųąĄ─æ¬ė├
ĪĪĪĪ▒Š╬─ęįŲ¾śI(y©©)╣▄└Ēą┼ŽóŽĄĮy(t©»ng)×ķ╗∙ĄAŻ¼Å─╠ĮėæCRM▒Š╔ĒĄ─╠ž³c│÷░l(f©Ī)Ż¼ĮY(ji©”)║ŽöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─įŁ└ĒĪóSQLSERVER2005Ą─BIŲĮ┼_ųąĄ─Ęų╬÷Ę■äš║═ł¾▒ĒĘ■䚯¼▀Mąąę╗éĆīŹ└²Ą─Ęų╬÷ĪŻī”CRMŽĄĮy(t©»ng)Ą─ę╗ą®ĻPµIąįŅIė“┤µį┌Ą─å¢Ņ}Ż¼╠ß│÷Ų┌═¹Ą─ĮŌøQĘĮĘ©ĪŻ
ĪĪĪĪ
ĪĪĪĪę╗Īó▒│Š░╦╝┐╝
ĪĪĪĪŻ©ę╗Ż®╔╠śI(y©©)ųŪ─▄Ė┼╩÷
ĪĪĪĪ╔╠śI(y©©)ųŪ─▄Ż©Business IntelligenceŻ¼║åĘQBIŻ®Ą─Ė┼─ŅūŅįń╩ŪGartner GroupĄ─Howard Dresnerė┌1996─Ļ╠ß│÷üĒĄ─ĪŻ╔╠śI(y©©)ųŪ─▄Ė┼─Ņ║Ł╔w┴╦▓ķįāł¾▒ĒĪóöĄ(sh©┤)ō■(j©┤)Ęų╬÷ĪóöĄ(sh©┤)ō■(j©┤)═┌Š“ĪóöĄ(sh©┤)ō■(j©┤)éõĘ▌║═╗ųÅ═Ą╚╦∙ėąęįÄ═ų·Ų¾śI(y©©)øQ▓▀×ķ─┐Ą─Ą─╝╝ąg╝░Ųõæ¬ė├ĪŻ
ĪĪĪĪ╔╠śI(y©©)ųŪ─▄Ą─ĻPµI╩ŪÅ─īŹļHĄ─ĀI▀\öĄ(sh©┤)ō■(j©┤)ųąŻ¼▀MąąöĄ(sh©┤)ō■(j©┤)ŅA╠Ä└ĒŻ¼╚╗║¾│ķ╚ĪŻ©ExtractionŻ®Īó▐D(zhu©Żn)ōQŻ©TransformationŻ®║═čb▌dŻ©LoadŻ®Ż¼╝┤ETL▀^│╠Ż¼└¹ė├Ė„ĘN╝╝ąg╗“╣żŠ▀Ż¼ūŅĮKĄ├ĄĮę╗éĆŲ¾śI(y©©)╝ēĄ─øQ▓▀ą┼ŽóĪŻ
ī”ė┌┴Ń╩█ąąśI(y©©)Ą─øQ▓▀ą┼Žó½@Ą├Ż¼═©▀^ę╗éĆ▒╚▌^ą╬Ž¾Ą─Ż¼Ė³┘NĮ³╬ęéā┴Ń╩█Ų¾śI(y©©)╚š│Żæ¬ė├Ą─▀^│╠üĒ▒Ē¼F(xi©żn)Ż¼╝┤öĄ(sh©┤)ō■(j©┤)ÄņĄ─ų¬ūR░l(f©Ī)¼F(xi©żn)Ż©Knowledge Discovery in DatabaseŻ¼KDD Ż®ĪŻČ°į┌┐ŲčąųąĘQĄ─“ų¬ūR░l(f©Ī)¼F(xi©żn)”Ż¼į┌╣ż│╠ŅIė“ę▓│Ż▒╗ĘQ×ķ“öĄ(sh©┤)ō■(j©┤)═┌Š“”ĪŻ
ĪĪĪĪŽ┬łDš╣╩Š┴╦ų¬ūR░l(f©Ī)¼F(xi©żn)Ą─▀^│╠Ż║
ĪĪĪĪ
ĪĪĪĪŻ©Č■Ż®CRMĖ┼╩÷
ĪĪĪĪį┌▓╝┘ćČ„•╬ķĀ¢Ę“Ą─╗∙ĄAąį蹊┐ĪČMeasured marketingĪĘųą├Ķ╩÷ĄĮŻ¼Įy(t©»ng)ėŗųą░l(f©Ī)¼F(xi©żn)Ž¹┘MŅ~į┌Ū░30%Ą─ŅÖ┐═žĢ½IĄ─Ž¹┘MŅ~╩Ū75%,Č°Ž¹┘MŅ~║¾30%Ą─ŅÖ┐═žĢ½IĄ─Ž¹┘MŅ~āHāH╩Ū3%ĪŻ▀@ūŃęįšf├„ŅÖ┐═į┌┘Å┘I─▄┴”╔ŽĄ─▓╗Š∙Ą╚ąįĪŻęįŅÖ┐═×ķųąą─Ą─┴Ń╩█Įø(j©®ng)Ø·īWĄ─ū┌ų╝╩ŪūīŅÖ┐═ØMęŌŻ¼īóŲ¾śI(y©©)Ą─ėąŽ▐Ą─┘Yį┤═Č╚ļĄĮūŅėąārųĄĄ─ŅÖ┐═╔Ē╔ŽŻ¼×ķūį╝║Ą─ųęš\ŅÖ┐═╠ß╔²Ė³ėąārųĄĄ─Ę■äšĪŻ▀@║═┴Ń╩█«a(ch©Żn)│÷╣▄└Ē╩Ū«ÉŪ·═¼╣żĄ─ĪŻ
ĪĪĪĪČ°ī”ė┌ę╗éĆ┐═æ¶ĻPŽĄ╣▄└ĒŽĄĮy(t©»ng)Ż¼Ųõų„ų╝ę▓į┌ė┌Ä═ų·Ų¾śI(y©©)═©▀^╝╝ąg╩ųČ╬Ż¼Ęų╬÷┐═æ¶Ą─ąą×ķ║═╦¹éāĄ─ārųĄŻ¼ęį╠ß╣®Ė³ā×(y©Łu)Ą─Ž¹┘MĘ■äš╝░┐═涾w“×ĪŻ
ĪĪĪĪ═©│ŻŻ¼CRMŽĄĮy(t©»ng)Ęų×ķĘų╬÷ą═Īó▀\ĀIą═Īóģf(xi©”)ū„ą═ĪŻī”ė┌ę╗éĆ┴Ń╩█Ų¾śI(y©©)Ą─┐═æ¶ĻPŽĄ╣▄└ĒŽĄĮy(t©»ng)Ż¼═©│Ż╩ŪęįĖ„ĘNĮķ┘|(zh©¼)Ą─┐©ū„×ķ▌d¾w╚źĮēČ©ŅÖ┐═Ą─╔ĒĘ▌Ż¼Å─Č°┘NĮ³ŅÖ┐═Ż¼Ę■äšŅÖ┐═ĪŻ╦∙ęįī”ė┌ę╗éĆ┴Ń╩█Ų¾śI(y©©)Ą─┐═æ¶ĻPŽĄ╣▄└Ē▒ž╚╗Ģ■╔µ╝░ĄĮ┐©╣▄└ĒŻ¼═¼Ģr║Ł╔w┐═æ¶Ęų╬÷║═£Ž═©Ą╚ĪŻ
ĪĪĪĪ═©│Żī”ė┌öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ąĶŪ¾Ż¼┐╔ęįĘų×ķŻ║
ĪĪĪĪ1Īó┐═æ¶Ė┼ørĘų╬÷Ż║┐═æ¶Ą─īė┤╬Īó’LļUĪóÉ█║├Īó┴ĢæTĄ╚Ż╗
ĪĪĪĪ2Īó┐═æ¶ųęš\Č╚Ęų╬÷Ż║╗∙ė┌ŅÉäe╣▄└ĒŻ¼┐╝▓ķ┐═æ¶ŅÉäe▐D(zhu©Żn)ęŲ║═ūā╣Ø(ji©”)Ż¼╝░┐╝▓ķĮø(j©®ng)Ø·ųęš\║═ĻPŽĄųęš\Ż╗
ĪĪĪĪ3Īó┐═æ¶└¹ØÖĘų╬÷Ż║▓╗═¼┐═æ¶╦∙Ž¹┘MĄ─«a(ch©Żn)ŲĘĄ─▀ģŠē└¹ØÖĪó┐é└¹ØÖŅ~Īóā¶└¹ØÖĄ╚Ż╗
ĪĪĪĪ4Īó┐═æ¶ąį─▄Ęų╬÷Ż║▓╗═¼┐═æ¶╦∙Ž¹┘MĄ─«a(ch©Żn)ŲĘ░┤ĘNŅÉĪóŪ■Ą└ĪóõN╩█Ąž³cĄ╚ųĖś╦äØĘųĄ─õN╩█Ņ~Ż╗
ĪĪĪĪ5Īó┐═æ¶╬┤üĒĘų╬÷Ż║īżšę┐═æ¶öĄ(sh©┤)┴┐ĪóŅÉäeĄ╚ŪķørĄ─╬┤üĒ░l(f©Ī)š╣┌ģä▌Ż¼ęįĀÄ╚Ī┐═æ¶Ż╗
ĪĪĪĪ6Īó┐═涫a(ch©Żn)ŲĘĘų╬÷Ż║ų„ę¬ßśī”╔╠ŲĘĄ─ĻP┬ō(li©ón)Ęų╬÷Ż¼╝░╔µ╝░Ą─╣®æ¬µ£ā×(y©Łu)╗»Ż╗
ĪĪĪĪ7Īó┐═æ¶┤┘õNĘų╬÷Ż║░³└©Ó]ł¾╗“ĮĄārĄ╚┤┘õN╗ŅäėĄ─╣▄└ĒĪŻ
ĪĪĪĪČ■Īóæ¬ė├īŹ└²
ĪĪĪĪŻ©ę╗Ż®ŅÖ┐═ŅÉäe╣▄└Ē
ĪĪĪĪ▒ŠīŹ└²Ą──┐Ą─╩Ūäō(chu©żng)Į©ę╗éĆ║åå╬Ą─ŅÖ┐═ĘųŅÉŻ¼į┌ŅÖ┐═ĘųŅÉĄ─╗∙ĄA╔ŽŻ¼▀MąąŽÓæ¬Ą─╔╠ŲĘŲĘŅÉ┘Å┘IĄ─Ęų╬÷ĪŻ
╗∙ė┌ŅÖ┐═ŅÉäe╣▄└ĒĄ─└ĒšōŻ¼▓╗┐╔─▄į┌Ęų╬÷Ģrų▒Įėßśī”å╬ę╗ŅÖ┐═▀MąąĘų╬÷Ż¼┐ŽČ©╩Ūī”═¼ę╗ŅÉäeĄ─ŅÖ┐═Ż¼▀MąąŽÓæ¬Ą─Ž¹┘Mąą×ķ┴ĢæTĘų╬÷Ą╚ĪŻ▀@Š═╚ń═¼╔╠ŲĘę¬▀MąąŲĘŅÉ╣▄└ĒĄ─Ą└└Ēę╗śėĪŻ«öų╗ėą▀MąąŅÖ┐═Ą─ŅÉäe╣▄└ĒĢrŻ¼▓┼─▄╚ź┐╝▓ķŅÉäe╚╦öĄ(sh©┤)▐D(zhu©Żn)ęŲ┴┐Ż¼▀@╩ŪĢ■åT╣▄└Ē│╔ą¦Ą─ę╗éĆųžę¬ųĖś╦ĪŻę▓ų╗ėą▀@śėŻ¼▓┼─▄ī”ūā╣Ø(ji©”)┬╩Ą╚ųĖś╦▀Mąą
┐╝▓ķĪŻ
ĪĪĪĪ╬ęéā═©│Ż▀MąąĄ─ŅÖ┐═ĘųŅÉŻ¼Č╝╩Ū└¹ė├┐═å╬┴┐╗“┘Å╬’Ņl┤╬äØę╗Ė∙ŠĆŻ¼üĒĮńČ©ĘųŅÉĄ─Ž¾Ž▐ĪŻČ°šµš²Ą─ŅÖ┐═Š█ŅÉŻ¼═©│Ż┐╝æ]┴╦┐═å╬ĪóŅl┤╬╗“š▀╩š╚ļĄ╚Ą╚ŠC║Žę“╦žČ°īŹ¼F(xi©żn)ĪŻ═©▀^║åå╬Ą─äØŠĆ╩ĮĘųŅÉŻ¼¤oĘ©▀_ĄĮ“╚╦ęį╚║Ęų”Ą─ą¦╣¹ĪŻ
ĪĪĪĪŻ©Č■Ż®Š█ŅÉĘų╬÷
ĪĪĪĪ Š█ŅÉ╦ŃĘ©ėą─▄┴”░l(f©Ī)¼F(xi©żn)ė├üĒī”öĄ(sh©┤)ō■(j©┤)▀MąąĘųĮMĄ─ļ[ąįūā┴┐Ż¼ę“┤╦ī”ė┌┴Ń╩█ąąśI(y©©)üĒšfŻ¼Š█ŅÉ╦ŃĘ©╩Ūę╗ĘNĘŪ│Ż┴„ąąĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ągĪŻ
ĪĪĪĪī”ė┌Š█ŅÉ╦ŃĘ©üĒšfŻ¼│Żė├Ą─ėąā╔ĘNŻ║K-ŲĮŠ∙║═K-ųąą─³cĪŻ
ĪĪĪĪį┌SQLSERVER2005 BI Development StudioųąĄ─Š█ŅÉ╦ŃĘ©ę▓ėąā╔ĘNŻ¼K-means╦ŃĘ©║═EM╦ŃĘ©Ż¼▀@ā╔ĘNČ╝╩Ūī┘ė┌K-ŲĮŠ∙╦ŃĘ©Ą─ĪŻ
ĪĪĪĪK-means╦ŃĘ©╩ŪęįŠÓļxųĄĄ─ŲĮŠ∙ųĄī”Š█ŅÉ│╔åT▀MąąĘų┼õŻ¼├┐éĆī”Ž¾╩Ūį┌ę╗éĆŠ█ŅÉųąŻ¼Š█ŅÉ║═Š█ŅÉų«ķg╗ź▓╗ųž»B, ═©│Ż▒╗šJ×ķ╩Ūė▓Š█ŅÉĪŻČ°EM╦ŃĘ©įćė├Ė┼┬╩▀MąąČ╚┴┐,ę╗éĆ³c┐╔─▄ī┘ė┌ČÓéĆŠ█ŅÉŻ¼├┐éĆŠ█ŅÉėą▓╗═¼Ą─Ė┼┬╩Ż¼Š█ŅÉų«ķg╩Ū┐╔ęįųž»BĄ─Ż¼═©│Ż▒╗ĘQ×ķ▄øŠ█ŅÉĪŻī”ė┌ļx╔óī┘ąįĄ─Š█ŅÉ╩Ū▀m║Ž╩╣ė├EM╦ŃĘ©Ą─ĪŻ
ĪĪĪĪMicrosoftĄ─Š█ŅÉ╦ŃĘ©ėąę╗éĆ┐╔╩š┐sįŁ└ĒŻ¼ī”ė┌ę╗éĆ┐╔╩š┐sĄ─┐“╝▄Ż¼«ö▀MąąųžÅ═ė¢ŠÜĢrŻ¼ī”ė┌▓╗Ģ■į┌Š█ŅÉų«ķgęŲäėĄ─öĄ(sh©┤)ō■(j©┤)Ż¼Č╝░č╦¹éāē║┐sŻ¼▓╗╝ė▌dĄĮā╚(n©©i)┤µŻ¼▀@śėŠ═ē║┐s┴╦ā╚(n©©i)┤µ┐šķgĪŻ
ĪĪĪĪSLQ Server Analysis Servicesėąā╔éĆų„ꬥ─öĄ(sh©┤)ō■(j©┤)═┌Š“?q©▒)”Ž¾Ż║═┌Š“ĮY(ji©”)śŗ║══┌Š“─Żą═ĪŻ═┌Š“ĮY(ji©”)śŗė├üĒČ©┴x═┌Š“å¢Ņ}Ą─ī”Ž¾Ż¼Č°═┌Š“─Żą═╩Ū═┌Š“╦ŃĘ©ī”═┌Š“ĮY(ji©”)śŗĄ─Š▀¾wæ¬ė├ĪŻ
ĪĪĪĪ ▒Š╣Ø(ji©”)ųąŽ┬├µĄ─└²ūėŻ¼╩Ūį┌SQL Server Analysis ServicesĘ■䚥─ŲĮ┼_╔ŽŻ¼ą┬Į©Ą─ę╗éĆanalysis servicesĒŚ─┐, æ¬ė├┐╔╩š┐sĄ─k-meansŠ█ŅÉ╦ŃĘ©─Żą═Ż¼ęį─│┤¾ą═│¼╩ąĮ³░ļ─ĻĄ─Ģ■åTŽ¹┘MöĄ(sh©┤)ō■(j©┤)╗∙ĄAŻ¼ų╗═©▀^┐═å╬┴┐║═Ņl┤╬ā╔éĆŠSČ╚Ż¼ī”Ģ■åT▀Mąą║åå╬ĘųŅÉĪŻ┐é╣▓Ęų│╔┴╦4ŅÉĢ■åTĪŻį┌║¾├µł¾▒Ēæ¬ė├ĢrŻ¼īó║åå╬Ą─ęįAĪóBĪóCĪóDüĒś╦ūRĪŻ╩ūŽ╚╚ńŽ┬łD’@╩ŠŻ║
ĪĪĪĪ
ĪĪĪĪąĶųĄĄ├ūóęŌĄ─╩ŪŻ¼į┌▀MąąöĄ(sh©┤)ō■(j©┤)ŅA╠Ä└ĒĄ─Ģr║“Ż¼ĒÜŽ╚▀MąąöĄ(sh©┤)ō■(j©┤)Ą─ŪÕŽ┤ĪŻīóę╗ą®└¼╗°öĄ(sh©┤)ō■(j©┤)ŪÕ│²Ż¼īóąĶꬥ─öĄ(sh©┤)ō■(j©┤)▀Mąą╝ė╣żĪŻ
ĪĪĪĪ
ĪĪĪĪī”ė┌SLQ Server Analysis ServicesĄ─═┌Š“ĮY(ji©”)╣¹Ą─░l(f©Ī)▓╝Ż¼┐╔ęįų▒Įė═©▀^DMXšZčį▀Mąą▓ķįāŻ¼╗“š▀═©▀^SQLSERVER2005 BI Development StudioüĒäō(chu©żng)Į©ł¾▒Ē─Żą═üĒš╣╩ŠĪŻł¾▒Ē─Żą═Ą─╩╣ė├į┌Ž┬ę╗╣Ø(ji©”)ųąöó╩÷ĪŻ▀@└’Ž╚šf├„Ž┬DMXšZčįĄ─╩╣ė├ĪŻ
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)═┌Š“öUš╣▓Õ╝■ (DMX) ╩Ūę╗ĘNšZčįŻ¼į┌ Microsoft SQL Server 2005 Analysis Services (SSAS) ųą┐╔ęį╩╣ė├įōšZčįäō(chu©żng)Į©║═╠Ä└ĒöĄ(sh©┤)ō■(j©┤)═┌Š“─Żą═ĪŻ┐╔ęį╩╣ė├ DMX äō(chu©żng)Į©ą┬öĄ(sh©┤)ō■(j©┤)═┌Š“─Żą═Ą─ĮY(ji©”)śŗĪó×ķ▀@ą®─Żą═Č©ą═▓óī”Ųõ▀Mąą×gė[Īó╣▄└Ē║═ŅA£yĪŻDMX ė╔öĄ(sh©┤)ō■(j©┤)Č©┴xšZčį (DDL) šZŠõĪóöĄ(sh©┤)ō■(j©┤)▓┘ū„šZčį (DML) šZŠõęį╝░║»öĄ(sh©┤)║═▀\╦ŃĘ¹śŗ│╔ĪŻŲ®╚ńį┌╔Ž└²ųą╚ń║╬šęĄĮ──ą®╩Ū“BŅÉĢ■åT”Ą─Ż║
ĪĪĪĪSELECT t.cardcode From [Guestsort] PREDICTION JOIN OPENQUERY([Hd31],
ĪĪĪĪ'SELECT [cardcode],[pjkdl],[pjkdpc] FROM [dbo].[guestsort] ') AS t
ĪĪĪĪON [Guestsort].[Pjkdl] = t.[pjkdl] AND [Guestsort].[Pjkdpc] = t.[pjkdpc]
ĪĪĪĪwhere Cluster() = 'BŅÉĢ■åT'
ĪĪĪĪ«ö╚╗╚ń╣¹▓╗Žļ▀@▓┐ĘųĢ■åTĄ─ĘųŅÉĮą“BŅÉĢ■åT”Ż¼Č°Ė─ĘQ×ķ“░ūŃyĢ■åT”╗“Ųõ╦¹ĘQ║¶Ż¼─Ū├┤ę▓╩Ū┐╔ęį═©▀^DMXšZčįüĒą▐Ė─═┌Š“─Żą═Ą─ā╚(n©©i)╚▌Ą├ĄĮĪŻ
ĪĪĪĪŻ©╚²Ż®ł¾▒Ē░l(f©Ī)▓╝
ĪĪĪĪ╔Žę╗╣Ø(ji©”)╠ߥĮ┴╦░l(f©Ī)▓╝öĄ(sh©┤)ō■(j©┤)┐╔ęį═©▀^Reporting ServicesüĒš╣╩ŠĪŻReporting Services╠ß╣®┴╦ę╗éĆäō(chu©żng)Į©Č©ųŲł¾▒ĒĄ─ÖCųŲŻ¼▀@éĆł¾▒Ē═©│Ż░³║¼╬─▒Š║═łDą╬Ż¼┐╔ęį═©▀^HTMLĪóEmailĪó┤“ėĪą╬╩Į║═Microsoft Office╬─Ön░l(f©Ī)▓╝ĪŻ╗∙ė┌WebĄ─ł¾▒Ē┐╔ęį╩ŪĮ╗╗ź╩ĮĄ─Ż¼═©▀^į÷╝ėł¾▒ĒģóöĄ(sh©┤)īŹ¼F(xi©żn)Į╗╗ź─┐Ą─ĪŻ
ĪĪĪĪ▒Š╣Ø(ji©”)ųąŽ┬├µĄ─└²ūėŻ¼╩Ū╗∙ė┌ŅÖ┐═ŅÉäe╣▄└ĒĄ─╗∙ĄA╔ŽŻ¼ī”AĪóBĪóCĪóD▓╗═¼ŅÉäeĄ─ŅÖ┐═╦∙ĻPą─Īó┘Å┘IĄ─╔╠ŲĘŲĘŅÉ▀MąąĄ─Įy(t©»ng)ėŗĘų╬÷ĪŻ╚ń╣¹īó▀@éĆ▀^│╠▀Mę╗▓Į╝ÜĘųĄ─įÆŻ¼─ŪŠ═╩Ūßśī”╔╠ŲĘ╝ēäeĄ─ĻP┬ō(li©ón)ęÄ(gu©®)ätĄ─æ¬ė├Ż¼▀@éĆį┌▀@└’▓╗▀MąąėæšōĪŻ▀@└’ų╗╩Ū═©▀^╔╠ŲĘŲĘŅÉ║═Ģ■åTŅÉäeĄ─ŠžĻć╩Įš╣╩ŠŻ¼▌^║åå╬Ąž¾w¼F(xi©żn)Reporting ServicesĄ─╣”─▄ĪŻ
ĪĪĪĪ═¼śėį┌SQLSERVER2005 BI Development Studio┐╔ęį╚źäō(chu©żng)Į©ę╗éĆReporting ServicesĒŚ─┐ĪŻöĄ(sh©┤)ō■(j©┤)į┤┐╔ęį╩ŪĻPŽĄöĄ(sh©┤)ō■(j©┤)ÄņŻ¼ę▓┐╔ęį╩ŪAnalysis ServicesĄ╚ĪŻŠ▀¾wĄ─▀^│╠▓╗├Ķ╩÷┴╦Ż¼Å─öĄ(sh©┤)ō■(j©┤)į┤ųąūŅĮKĄ─ł¾▒Ē╬─▒Š╗“łDą╬Ą╚Ż¼▀Mąą╔·│╔Īó▓┐╩Ż¼ūŅĮK┐╔ęį═©▀^webĄ─ĘĮ╩Į▀Mąą×gė[ĪŻ Ž┬łD╩ŠęŌ┴╦ę╗éĆ║åå╬öĄ(sh©┤)ō■(j©┤)Ą─░l(f©Ī)▓╝Ż║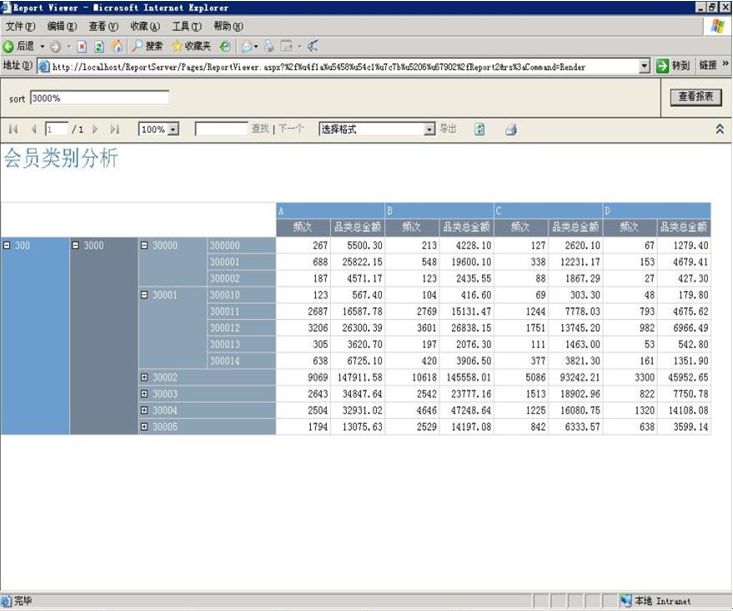
ĪĪĪĪ═©▀^webš╣╩ŠĄ─ŠžĻćĖ±╩ĮŻ¼ąą┤·▒Ē╔╠ŲĘŅÉäeŻ¼┴ą┤·▒ĒĢ■åTŅÉäeŻ¼ęį’@╩Š▓╗═¼ŅÉäeĢ■åTī”▓╗═¼ŲĘŅÉ╔╠ŲĘĄ─┘Å┘IŪķørĪŻ
ĪĪĪĪ═¼Ģr╔ŽłDę▓╩ŠęŌ┴╦ę╗éĆĮ╗╗źĄ─▀^│╠Ż¼┐╔ęį═©▀^ė├æ¶ųĖČ©Ą─╔╠ŲĘŅÉäeüĒ▓ķ┐┤Ėą┼d╚żĄ─öĄ(sh©┤)ō■(j©┤)ĪŻ▒╚╚ń▓ķ┐┤ųąŅÉ3000Ą─╔╠ŲĘ▒╗AĪóBĪóCĪóD╦─ŅÉĢ■åTĄ─┘Å┘IŅl┤╬╝░ŲĘŅÉĮŅ~ŪķørĪŻ«ö╚╗ę▓┐╔ęįį÷╝ėŲõ╦¹Ą─▓ķįāŚl╝■ĪŻ
ĪĪĪĪī”Ėą┼d╚żĄ─ŅÉäeų¦│ųśõą╬ĮY(ji©”)śŗĄ─ūįė╔š╣ķ_Ż¼Ž┬Ń@ĄĮąĪŅÉŻ¼ūėŅÉĪŻ╚ń╔ŽłDĄ─30000ąĪŅÉ║═30001ąĪŅÉŠ═š╣ķ_├„╝ÜĄĮĖ„ūįĄ─ūėŅÉųąĪŻ
ĪĪĪĪī”ė┌ł¾▒ĒĄ─ĮY(ji©”)╣¹┐╔ęįī¦│÷ĄĮXML,HTML,PDF,EXCELĄ╚Ą╚╬─╝■ųąĪŻ
ĪĪĪĪł¾▒ĒŲĮ┼_ų¦│ų═¼Ģrę▓ų¦│ųī”Ė„ĘNĮŪ╔½Ą─ÖÓŽ▐╣▄└Ē╝░╚š│ŻĄ─ėåķåĘ■䚥╚ĪŻ
ĪĪĪĪ╚²Īóæ¬ė├Ū░Š░
ĪĪĪĪÅ──┐Ū░Ą─īŹļHæ¬ė├üĒ┐┤Ż¼Š█ŅÉĘų╬÷ū„×ķöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ę╗ĘN╦ŃĘ©─Żą═Ż¼▀Ćėą║▄ČÓąĶę¬ųĄĄ├╚źš{(di©żo)š¹Ą─ĄžĘĮŻ¼Ų®╚ńŻ║╚ń║╬öĄ(sh©┤)ō■(j©┤)ŅA╠Ä└ĒŻ¼╚ń║╬╠▐│²┤¾ą═┤┘õNĄ╚Ż¼įņ│╔Ą─öĄ(sh©┤)ō■(j©┤)«Éäė……
ĪĪĪĪČ°ī”ė┌CRM▒Š╔ĒĄ─7┤¾Ęų╬÷ąĶŪ¾Ż¼ę▓ąĶę¬Ė³ČÓĄž═┌Š“─Żą═▀MąąīŹ█`ĪŻ▒╚╚ń┐╝▓ķŅÖ┐═ŅÉäe▐D(zhu©Żn)ęŲĢrŻ¼┐╔ęį╩╣ė├ą“┴ąŠ█ŅÉ╦ŃĘ©ĪŻ«a(ch©Żn)ŲĘĘų╬÷ĢrŻ¼┐╔ęį╩╣ė├ĻP┬ō(li©ón)ęÄ(gu©®)ätĪŻČ°ī”ė┌═¼ę╗ĘNśI(y©©)äšł÷Š░Ż¼æ¬ė├▓╗═¼╦ŃĘ©ę▓īóĄ├ĄĮ▓╗═¼Ą─ĮY(ji©”)╣¹ĪŻę“┤╦┐╔ęį═©▀^═┌Š“£╩┤_ąįłD▒ĒŻ¼ī”═┌Š“─Żą═▒Š╔Ē▀Mąą▓╗öÓĄ─ą▐š²ĪŻ
ĪĪĪĪ┐╔ęįŅAŲ┌į┌╬┤üĒĄ─æ¬ė├▀^│╠ųąŻ¼ĮY(ji©”)║Ž╔╠śI(y©©)ųŪ─▄└ĒšōĄ─æ¬ė├Ż¼═©▀^ŅÖ┐═ĻPŽĄ╣▄└ĒŻ¼īó×ķŅÖ┐═ĦüĒĖ³├└║├Ą─Ž¹┘M¾w“ׯ¼Įo┴Ń╩█╔╠ĦüĒĖ³ČÓĄ─õN╩█╠ß╔²ĪŻ
